Базове поняття селекторів
У контексті автоматизації тестування поняття “селектор” використовується для ідентифікації елементів на веб-сторінках або в інших інтерфейсах програмного забезпечення. Селектори – це унікальні параметри або шляхи, за допомогою яких автоматизовані тестові скрипти знаходять та взаємодіють з елементами інтерфейсу для виконання різних дій, таких як клік, введення тексту, перевірка стану тощо.
Основні види селекторів:
- XPath: Це мова запитів до елементів веб-сторінок, що дозволяє шукати елементи за їхньою структурою або розташуванням в HTML-коді сторінки.
- CSS-селектори: Це шляхи до елементів, визначені за допомогою CSS-синтаксису, які використовуються для вибору елементів за їх класами, ідентифікаторами, тегами тощо.
- ID або ім’я елемента: Це унікальні ідентифікатори або імена елементів, які можна використовувати для знаходження конкретного елемента на сторінці.
- Локатори за вмістом: Можуть використовуватися ключові слова чи тексти, які вказують на унікальність елемента (наприклад, текст на кнопці чи посиланні).
- Локатори за атрибутами: Можуть використовуватися атрибути елемента, такі як ідентифікатор (id), клас (class), атрибути тегів тощо.
Використання правильних селекторів дуже важливе у написанні надійних і стабільних тестів. Якщо селектор не унікальний або нестабільний, тест може впасти через зміни у веб-сторінці. Тому важливо обирати найбільш стійкі ідентифікатори елементів, які не будуть змінюватися під час розвитку програми або сайту.
Основні аспекти селекторів, особливо в контексті автоматизації тестування, включають:
- Унікальність: Селектори повинні бути унікальними та ідентифікувати лише один елемент на сторінці. Це дозволить уникнути конфліктів та точно визначити цільовий елемент.
- Стабільність: Важливо обирати стабільні селектори, які не змінюються часто. Ідентифікатори, які стабільні впродовж розвитку продукту, зменшують ймовірність виникнення помилок у тестах через зміни в інтерфейсі.
- Читабельність: Селектори повинні бути зрозумілими та читабельними для того, щоб інші розробники чи тестувальники легко зрозуміли, який елемент вони ідентифікують.
- Ідентифікація згідно з контекстом: Використовуйте селектори, які відображають контекст та мають зв’язок зі структурою сторінки чи програми. Наприклад, використання CSS-класів, які відображають функціональність елемента, може полегшити зрозуміння його призначення.
- Універсальність: Створюйте селектори, які можна використовувати на різних версіях браузерів або платформ. Це допоможе забезпечити стабільність тестів на різних середовищах.
- Інкапсуляція: Якщо можливо, обирайте селектори, які відображають інкапсуляцію елементів, тобто селектори, які знаходяться в межах конкретного блоку чи компонента.
- Точність та ефективність: Використовуйте селектори, які точно вибирають цільовий елемент та водночас є ефективними для пошуку.
Загальний підхід полягає в тому, щоб обирати селектори, які забезпечують надійну ідентифікацію цільових елементів, зменшують вплив змін у коді та забезпечують стабільність автоматизованих тестів.
XPATH селектори (ч.1)
XPath (XML Path Language) – це мова запитів, яка використовується для навігації та вибору об’єктів у XML-документах. У контексті веб-розробки та автоматизації тестування, XPath використовується для ідентифікації елементів веб-сторінок, зазвичай у тестових скриптах для автоматизованого тестування.
В автоматизації тестування XPath застосовується для ідентифікації та перевірки веб-елементів. У практичному розгляді XPath є послідовністю кроків, яка описує, як перейти до якогось потрібного вузла (або групи вузлів) у XML-документі. Вузлом може вважатися елемент сторінки, атрибут, текст, коментар, або будь-яка інша частина сторінки, що дуже корисно в автоматизації веб-сайту, а також і при тестуванні мобільних додатків.
Основні аспекти XPath селекторів:
- Вирази шляху (Path Expressions): XPath використовує вирази шляху для навігації через елементи XML-структури. Наприклад, вираз /bookstore/book знайде всі елементи <book>, які знаходяться в <bookstore>.
- Локатори елементів: XPath дозволяє використовувати різні локатори для вибору елементів. Це може бути за назвою тегу, атрибутом, текстовим вмістом, індексами, відносними шляхами тощо.
- Абсолютні та відносні шляхи: Абсолютні шляхи починаються з кореневого елемента документа (/), тоді як відносні шляхи вказують на елементи відносно поточного контексту.
- Предикати: XPath має можливість використовувати предикати для фільтрації вибору елементів за певними умовами. Наприклад, //div[@class=’example’] вибирає всі <div> елементи з класом example.
- Осьові відносини: В XPath використовуються осьові відносини (parent, child, sibling) для навігації між елементами документа.
- Функції: XPath має багато вбудованих функцій для обробки даних та виконання різних операцій. Наприклад, функція text() використовується для вибору текстового вмісту елементів.
- Можливості пошуку: XPath може використовуватися для знаходження елементів за різними критеріями, що дозволяє точно ідентифікувати цільові елементи.
Використання XPath селекторів дозволяє точно ідентифікувати елементи на сторінці та виконувати різні дії з ними в автоматизованих тестах. Однак, важливо вибирати стійкі та ефективні селектори, щоб уникнути проблем з тестами під час змін в інтерфейсі. Далі детально розглянемо деякі аспекти використання.
Абсолютний xpath починається з одного слеша ( / ) і вказує на повний шлях з кореневого вузла (root) до цільового (target). Наприклад, такий вираз у XPath:
/html/body/div[1]/h1означає: “вибрати перший div-елемент під body-елементом під html-елементом, і далі вибрати його вкладений (або дочірній, child) h1-елемент”.
Відносний шлях починається з дабл-слеша (двох //) і вказує на шлях з будь-якого вузла (=нода) який відповідає критеріям до цільового вузла. Наприклад,
//div[@id='main’]— означає вибрати будь-який div-елемент, що має id-атрибут зі значенням ‘main’.
Запис виразів XPath залежить від того, який елемент потрібно знайти. Базовий синтаксис:
//tagname[@attribute='value’]Це означає «вибрати будь-який tagname-елемент, що має атрибут зі значенням ‘value’». Значення завжди в одинарних лапках, атрибути – у квадратних дужках. Наприклад, //input[@type='text'] – це означає «вибрати будь-який input-елемент, що має атрибут типу зі значенням ‘text’».
//– почати пошук з будь-якого місця на сторінціinput– HTML-тег, тобто будь-який тег в HTML (наприклад, p, button, span, div …)type– атрибут, будь-який атрибут в HTML (id, class, link, src, alt…)text– значення атрибута type. Ще приклад://a[@href='<https://google.com>’]– означає «вибрати будь-який елемент з href-атрибутом ‘google.com‘».
У XPath широко застосовуються логічні оператори типу AND, OR та NOT, для вказівки кількох умов пошуку та поєднання умов.

Наприклад, //input[@type='text' AND @name='username’] означає «вибрати будь-який input-елемент, що має одночасно атрибут типу зі значенням ‘text’ та атрибут імені зі значенням ‘username’». //a[@href='<https://google.com>' OR @class='link’] означає «вибрати будь-який якірний елемент, що має або href-атрибут зі значенням https://google.com, або з атрибутом класу зі значенням link». //div[NOT(@id)] означає «вибрати будь-який div-елемент, який не має id-атрибута».
Також у XPath застосовуються функції типу text(), contains(), starts-with() і ends-with() для перевірки точного чи часткового збігу тексту (текстових значень).
Приклади:
//h1[text()='Welcome'] – це вибрати будь-який h1-елемент, що має текстове значення ‘Welcome’. //p[contains(text(),'Hello')] – вибрати будь-який p-елемент, що містить текстове значення ‘Hello’. //img[starts-with(@src,'logo')] — вибрати будь-який малюнок із src-атрибутом, який починається зі значення ‘logo’ //span[ends-with(@id,'_title')] – вибрати будь-який span-елемент, який закінчується значенням ‘_title’.
XPATH селектори (ч.2)
XPATH використовує вісі для навігації та вибору елементів у XML-документах чи HTML-сторінках. Вісі – це напрямки або відносини між елементами, які дозволяють вказувати шлях до елементів відносно їхньої позиції у структурі документа. Вони визначають, які елементи слід вибирати та в якому порядку.
Базовий синтаксис вісі XPATH виглядає так: axe::tagName[@attribute='value’]
Основні вісі в XPath:
- child (дитина): Вісь child вказує на всіх прямих дітей вказаного батьківського елемента. Наприклад, div/child::p вибере всі <p> елементи, які є прямими дітьми від <div>.
- parent (батько): Вісь parent вказує на батька поточного елемента. Наприклад, p/parent::div вибере <div> елементи, які є батьками для <p>.
- ancestor (предків): Вісь ancestor вибирає всіх предків поточного елемента. Наприклад, //p/ancestor::div вибере всі <div> елементи, які є предками для всіх <p> на сторінці.
- descendant (нащадки): Вісь descendant вибирає всі нащадки вказаного елемента. Наприклад, div/descendant::p вибере всі <p> елементи, які є нащадками <div>.
- following (наступний): Вісь following вибирає всі елементи, які знаходяться після поточного елемента на тому ж рівні вкладеності. Наприклад, p/following::div вибере всі <div> елементи, які знаходяться після елементів <p>.
- preceding (попередній): Вісь preceding вибирає всі елементи, які знаходяться перед поточним елементом на тому ж рівні вкладеності. Наприклад, p/preceding::div вибере всі <div> елементи, які знаходяться перед елементами <p>.
- self (сам): Вісь self вибирає сам поточний елемент. Наприклад, div/self::div вибере всі елементи <div>.
Використання вісей дозволяє точно вказувати, які елементи потрібно вибирати в XPath-запитах та як навігувати через структуру документа для вибору потрібних елементів для автоматизації тестування чи парсингу даних.
Роздивимось детально основні вісі XPATH, які можуть стати у нагоді при роботі з автоматизацією тестування ui.
Parent – вибирає верхній (батьківський) вузол (стосовно поточного вузла):
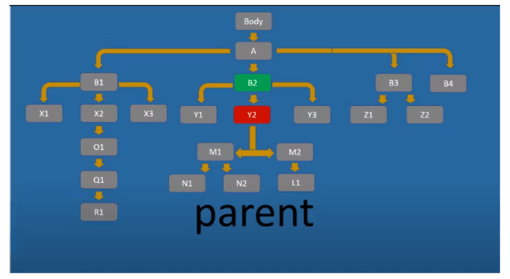
//div[@id='Y2']/parent::* — вибрати будь-який елемент, що є прямим батьківським для div-елемента з id ‘Y2’, це B2 у нашому випадку.
Ancestor вибирає всі предки поточного вузла. Іншими словами, перший батьківський і все старший, тобто «у напрямку до коріння дерева»:
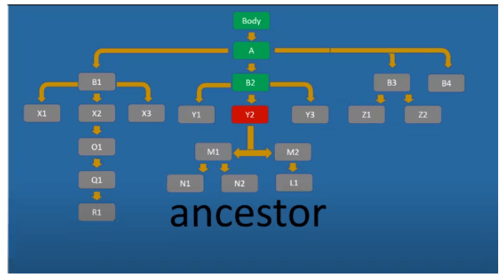
//div[@id='Y2']/ancestor::div[@id='B2'] вибирає div-елемент з id ‘B2’, який є предком div-елемента з id ‘Y2’. //div[@id='Y2']/ancestor::div[@id='A'] – вибрати div-елемент з id A, що є предком div-елемента з id ‘Y2’.
Ancestor-or-self вибирає всі предкові елементи поточного вузла, включаючи сам поточний вузол.
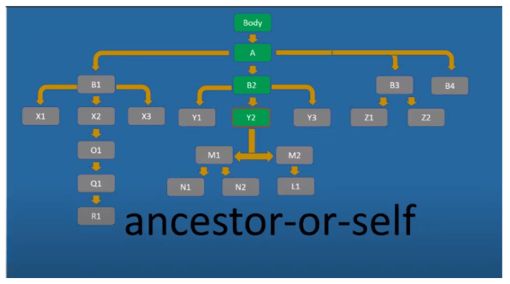
Тобто те саме що Ancestor, і плюс сам цей вузол.
Child вибирає безпосередні елементи-нащадки (але перші дочірні) поточного вузла:
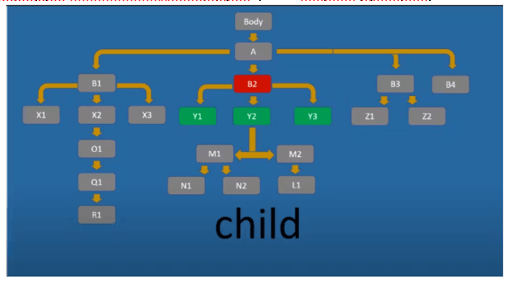
//div[@id='B2']/child::* — вибрати всі елементи, які є прямими нащадками div-елемента з id B2. //div[@id='B2']/child::div[@id='Y2'] – вибір всіх div-елементів з id Y2, прямих нащадків div-елемента з id B2.
Descendant дозволяє вибрати всіх нащадків (у всіх рівнях) поточного вузла.
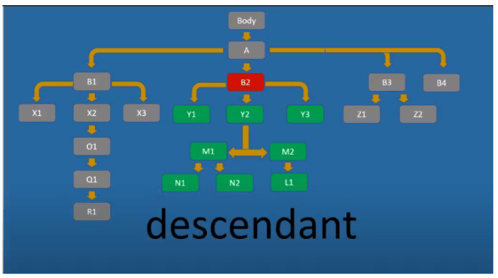
Вираз //div[@id=’B2′]/descendant::* вибирає всі елементи, які є нащадками div-елемента з id B2. //div[@id=’B2′]/descendant::div[@id=’L1′] — вибрати div-елементи-нащадки від div-елемента з id L1.
XPATH селектори (ч.3)
Following дозволяє вибрати всі елементи в документі, що йдуть після тега поточного вузла, що закриває. Іншими словами, нижче поточного елемента по дереву (на всіх рівнях), але виключаючи власних нащадків:
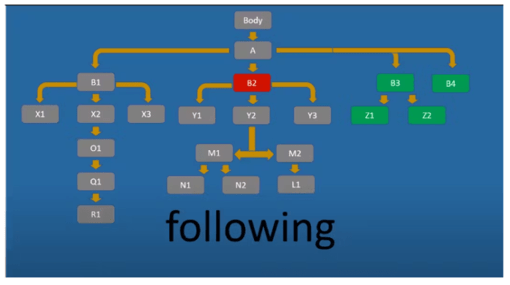
//div[@id='B2']/following::* — вибрати всі div-елементи нижче за поточний елемент з id B2.
Following-sibling обирає усі елементи “братського”, тобто того ж рівня (рівня цього вузла):
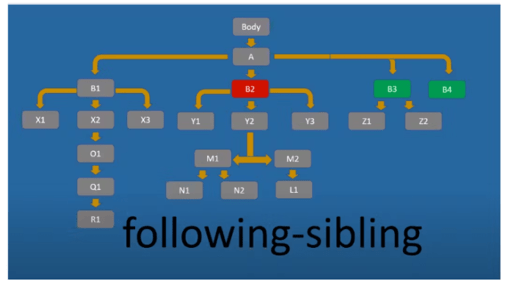
//div[@id='B2']/following-sibling::* вибирає всі елементи на тому ж рівні, що і div-елемент з id B2, і нижче його в дереві. Інакше кажучи, «усі братні».
Preceding аналогічний Following, але у зворотний бік, тобто вибирає всі елементи вище вказаного:
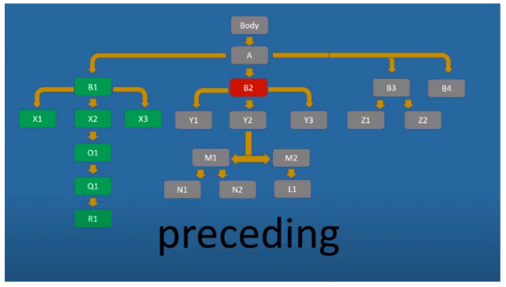
//div[@id='B2']/preceding::* вибирає всі елементи, що йдуть перед div-елементом з id B2.
Preceding-sibling працює аналогічно Preceding, але вибирає тільки на тому ж рівні і перед зазначеним:
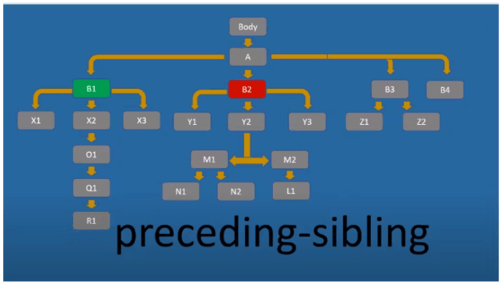
//div[@id='B2']/preceding-sibling::* вибирає елементи, що йдуть перед div-елементом з id B2 на тому ж рівні.
Переваги використання XPATH селекторів у автоматизації тестування:
- Гнучкість і потужність: XPATH дозволяє точно вибирати елементи на веб-сторінках чи в XML-документах за різними критеріями, такими як назви тегів, атрибути, текстовий вміст тощо, що робить його потужним і гнучким інструментом для локалізації елементів.
- Можливість вибору складних структур: XPATH дозволяє працювати зі складними структурами документів, такими як вибір елементів відносно ієрархічних відносин, що дає можливість точно локалізувати потрібні елементи навіть у вкладених структурах.
- Підтримка різних типів атрибутів: XPATH може використовуватися для вибору елементів на основі різних атрибутів, таких як ідентифікатори, класи, data-атрибути, що дозволяє шукати елементи за різними критеріями.
- Універсальність: XPATH може бути використаний на різних типах веб-сторінок та мовах розмітки, таких як HTML, XML, інші XML-подібні формати, що робить його універсальним засобом вибору елементів.
Недоліки використання XPATH селекторів у автоматизації тестування:
- Складність написання: Написання складних XPATH виразів може бути важким для розуміння та підтримки, особливо для новачків. Деякі складні вирази можуть бути довгими та складними для розуміння.
- Підвищена вразливість до змін: Якщо структура веб-сторінок чи документів змінюється, XPATH може втратити свою актуальність, що призведе до виникнення помилок у тестах.
- Швидкість виконання: Деякі складні XPATH вирази можуть бути менш ефективними у виконанні, що може впливати на продуктивність тестів.
- Залежність від структури документа: XPATH селектори можуть бути більш залежними від конкретної структури документа, тому їх слід підтримувати та оновлювати при змінах у веб-сторінках.
Усі ці фактори слід враховувати при виборі та використанні XPATH селекторів у автоматизованих тестах.
CSS селектори (ч.1)
CSS (Cascading Style Sheets) селектори використовуються для визначення стилів та вигляду елементів веб-сторінки в мові розмітки HTML або XML. У контексті автоматизованого тестування, CSS селектори використовуються для ідентифікації елементів на веб-сторінці для подальшої взаємодії з ними, такої як отримання тексту, клік або заповнення форм.
Селектори CSS ідентифікують різні елементи в DOM, і вони впливають або підключаються до цих частин інтерфейсу. Селектори CSS бувають різних типів. Це головним чином тому, що на відміну від дерева або карти, що є у XPath, селектори мають фактичні імена та категорії.
Загальний вигляд CSS селектора: button[type=‘submit’].button_submit, де button – тег, [type=‘submit’] – атрибут, .button_submit – клас.
Основні аспекти CSS селекторів:
- Елементи за типом, класом, або ідентифікатором: CSS дозволяє вибирати елементи за їхніми тегами, класами або ідентифікаторами. Наприклад, div вибере всі <div> елементи, .class вибере всі елементи з класом class, #id вибере елемент з ідентифікатором id.
- Вкладеність та ієрархія: CSS селектори можуть вибирати елементи відповідно до їхньої вкладеності або ієрархії на сторінці. Наприклад, div p вибере всі <p> елементи, які знаходяться всередині <div>.
- Атрибути: CSS селектори можуть використовувати атрибути елементів для їхнього вибору. Наприклад, [attribute=’value’] вибере елементи з вказаним атрибутом та значенням.
- Псевдокласи та псевдоелементи: CSS має псевдокласи та псевдоелементи, які дозволяють стилізувати елементи за різними умовами. Наприклад, :hover стилізує елемент при наведенні миші, ::before створює псевдоелемент перед вмістом елемента.
- Комбіновані селектори: CSS дозволяє комбінувати різні селектори для точнішого вибору елементів. Наприклад, div.container вибере всі <div> елементи з класом container.
- Універсальні селектори: CSS має універсальні селектори, які вибирають всі елементи сторінки. Наприклад,
“***”**вибере всі елементи.
Використання CSS селекторів у автоматизованому тестуванні дозволяє точно ідентифікувати елементи на сторінці та взаємодіяти з ними для виконання різних дій у тестах. Важливо вибирати стійкі та ефективні селектори, щоб уникнути проблем з тестами при змінах у веб-сторінці.
| Селектор | Приклад | Роз’яснення |
| .class | .some_class | Знаходить всі елементи з класом “some_class” |
| .class1.class2 | .user1.user2 | Знаходить всі елементи, у яких присутні класи “user1” та “user1”, напр <div class=”user1 user2 user3”> |
| .class1 .class2 | .user1 .user2 | Знаходить всі елементи з класом user2, які знаходяться у будь якому рівні вкладеності всередині елементів з класом user1 |
| [class] | [class=”user1 user2”] | Знаходить всі елементи, у яких class містить виключно user1 та user2, напр <div class=”user1 user2”></div> |
| #id | #user | Знаходить елемент з id=”user” |
| * | * | Використовується для знаходження всіх елементів на сторінці, або для знаходження співпадіння за частиною назви атрибуту, наприклад [name*=”somename”] знайде елемент, у якого частина назви атрибуту name співпадає з вказаною, тобто будуть знайдені такі як <div name=”12somename”>, <div name=”somename34”> або <div name=”12somename34”> |
| ^ | a[href^=”https:”] | Знайде усі посилання, атрибути href яких починаються з “https:” |
| $ | a[href$=”.pdf”] | Знайде усі посилання, атрибути href яких закінчуються на “.pdf” |
| element | p | Вибір всіх елементів з тегом <p> на сторінці |
| element.class | p.intro | Вибір всіх елементів з тегом <p class="intro"> на сторінці |
| element,element | div,p | Вибір всіх елементів з тегaми <div> та <p>на сторінці |
| element element | div p | Вибір всіх елементів з тегом <p> , які є нащадками елементів з тегами <div> |
| Селектор | Приклад | Роз’яснення |
| element>element | div>p | Вибір всіх елементів з тегом <p> , де батьківськими є елементи з тегами <div> |
| element:nth-child(n) | ul li:nth-child(2) | Вибирає n-ий дочірній елемент, у випадку з прикладу буде знайдено другий елемент списку:<ul><li>Другий</li> |
| element:first-child | ul li:first-child | Вибирає перший дочірній елемент:<ul><li>Перший</li><li>Другий</li> |
| element:last-child | ul li:last-child | Вибирає останній дочірній елемент:<ul><li>Перший</li><li>Другий</li><li>Третій</li> |
| element[attr=”value”] | input[type=”text”] | Вибирає елемент з вказаним атрибутом, з прикладу буде обрано елемент <input type=”text”> |
| element[attr=”value”][attr=”value”] | input[type=”text”][name=”email”] | Вибирає елемент з вказаними декількома атрибутами, з прикладу буде обрано елемент <input type=”text” name=”email”> |
| :not | div:not(.example) | Вибір всіх елементів div, які не мають класу example |
| :not | .content:not(ul li) | Вибір всіх елементів з класом content, які не є елементами списку |
| :not | button:not([type]) | Вибір всіх елементів button, які не мають атрибуту type |
| :not | a:not(.external):not([target=”_blank”]) | Вибір всіх елементів з тегом а, які не мають класу external та не мають атрибуту target=”_blank” |
CSS селектори (ч.2)
Для побудови селекторів можуть бути використані певні послідовності. Наприклад маємо розмітку виду:
<form class="form_upload>
<div>
<div class="row_element_3 row tile_fixed">
<div class-"button_cell wrapper_tile">
<button type-"submit" class-"button_submit wrapper_button"></button>
</div>
</div>
</div>
</form>в якій необхідно знайти кнопку з класом submit.
Можуть бути використані такі підходи:
form > div > div > div > button.submit– такий варіант використовує жорстку послідовність знаходження певного елемента та гарантує саме таку структуру вузлів;form button.submit– такий варіант забезпечить знаходження кнопки у формі без жорсткої прив’язки до внутрішньої структури вузлів самої форми.
Інший приклад розмітки, в якій необхідно знайти елементи на одному рівні:
<form class="form_upload>
<div>
<div class="row_element_3 row tile_fixed">
<div class-"button_cell wrapper_tile">
<div class="content"></div>
<span data-id="link"> </span>
<button type-"submit" class-"button_submit wrapper_button"></button>
</div>
</div>
</div>
</form>[data-id=”link”] + button – знайде кнопку button, у якого на тому самому рівні є елемент з data-id=‘link’.
CSS селектори широко використовуються у тестуванні веб-додатків для ідентифікації та взаємодії з елементами на веб-сторінках. Ось деякі переваги та недоліки використання CSS селекторів у автоматизації тестування:
Переваги:
- Простота використання: CSS селектори досить легкі у використанні та зрозумілі для багатьох розробників та тестувальників, оскільки їх синтаксис є стандартним для веб-розробки.
- Гнучкість вибору елементів: CSS селектори надають можливість точно вибирати елементи за різними критеріями, такими як класи, ідентифікатори, атрибути, структурні зв’язки, що дозволяє створювати стійкі та гнучкі тести.
- Універсальність: CSS селектори можуть бути застосовані на багатьох веб-сторінках, оскільки вони використовують стандартні правила вибору елементів.
- Розширені можливості вибору: З CSS селекторами можна виконувати різноманітні вибори елементів, такі як пошук елементів за попередніми, наступними елементами, дочірніми елементами, елементами певного типу тощо.
Недоліки:
- Залежність від структури сторінки: Іноді зміни у структурі HTML можуть призвести до того, що раніше працюючі CSS селектори перестануть бути актуальними, що призведе до виникнення помилок у тестах.
- Вразливість до змін вигляду: Якщо стиль відображення елементів на веб-сторінці зміниться, тести, що використовують CSS селектори для ідентифікації, можуть стати непрацездатними.
- Складність написання складних селекторів: Деякі складні селектори можуть бути складними для розуміння та підтримки, що вимагає додаткового часу на їхнє створення та розуміння.
- Проблеми з переносом: CSS селектори можуть не завжди коректно працювати на різних платформах чи браузерах через різні імплементації CSS.
- Швидкість виконання: Деякі складні селектори можуть бути менш ефективними у виконанні, що може впливати на продуктивність тестів.
При використанні CSS селекторів у тестуванні важливо бути уважним та вибирати стійкі, прості та ефективні селектори для забезпечення стабільності тестових сценаріїв.
TDD
Методологія розробки через тести (Test-Driven Development, TDD) – це підхід до розробки програмного забезпечення, який передбачає написання тестів перед написанням функціонального коду. Основними аспектами TDD є цикл розробки, фокус на тестуванні та створення програми, яка задовольняє вимоги.
Цикл розробки TDD складається з трьох етапів:
- RED (Червоний):Написання тесту, який перевіряє очікуване поведінку функції або модуля, який має бути реалізований.
- Тест, як правило, не пройде (тобто буде червоним), оскільки функціонал ще не реалізований.
- GREEN (Зелений):Написання мінімального коду, який дозволяє тесту пройти (стати зеленим). Мета – лише пройти тест, навіть якщо це тимчасовий або примітивний функціонал.
- REFACTOR (Рефакторинг):Оптимізація та поліпшення коду без зміни поведінки. Мета – покращення читабельності, видалення дублювання, оптимізація швидкодії тощо.
- Після рефакторингу важливо переконатися, що тести все ще проходять.
Основні аспекти TDD:
- Тестування як перший крок: Розробка тестів перед розробкою функціональності. Тест стає специфікацією та вимогою до коду.
- Ітеративність та інкрементальність: Програма розробляється в невеликих ітераціях. Кожен цикл (RED-GREEN-REFACTOR) – це мініатюрний крок у напрямку розвитку функціоналу.
- Регулярний рефакторинг: Використання рефакторингу для покращення коду та його архітектури без зміни поведінки програми.
- Автоматизація тестування: Важливо мати автоматизовану суіту тестів, яка може бути запущена при будь-яких змінах коду для виявлення проблем.
- Визначеність та прозорість коду: Тестовий набір стає частиною документації, яка описує очікуване поведінку коду.
Розглянемо детально процес розробки програм методом TDD:
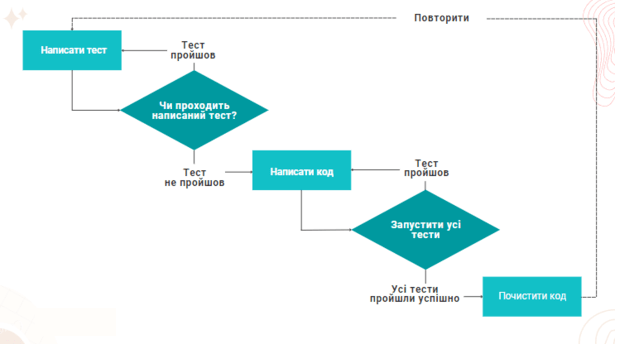
Написання тестів
Тести є програмними одиницями, що реалізують перевірку відповідності коду програми вимогам до функціональності, сформульованим у технічному завданні (ТЗ). Тести доцільно створювати на основі ТЗ, створеного замовником проекту. В такому разі їх перевірка на здійсненність може здійснюватися за замовника. Для створення, а також автоматизації запуску, як правило, використовуються ті ж Фреймворки, що і для створення програм. Тести пишуться для невеликих, найбільш критичних ділянок програми, схильних до частих змін. Метод TDD спочатку розглядався, як найбільш підходящий для таких ділянок, і тому отримав назву «екстремальне програмування».
Перевірка виконання тесту
Коли тест готовий, одразу ж виконується його перевірка на здійсненність. Очевидно, що без готового блоку програми тест ніяк не зможе пройти перевірку. Це означає, що тест попередньо написаний правильно. Якщо ж тест перевірку все-таки проходить, це може означати таке: або він невірний, або дана функціональність вже реалізована в програмі, і тоді він не має сенсу. У такому разі тест відправляється на доопрацювання, тобто цикл замикається.
Написання коду програми
Код, зазвичай, пишеться для реалізації лише однієї функціональності програми за допомогою одного з відомих Фреймворків, який має свої бібліотеки. По суті, метою створення коду є у разі задоволення вимог, встановлених у тесті. Таким чином, мінімізується його розмір та виключається непотрібна надмірність.
Комплексна перевірка
Комплексна перевірка готового коду на відповідність до вимог тестів. На цьому етапі здійснюється запуск тестів для готової ділянки коду програми та виявлення «нестиковки» при їх виконанні. Якщо тести успішно виконуються, код передається на наступний етап обробки – рефакторинг. Якщо ні, код повертається на доопрацювання.
Оптимізація коду програми
Ціль цього етапу – оптимізувати код зсередини, залишивши його «зовнішню» функціональність. Сюди відноситься, зокрема, зменшення надмірності коду до допустимого рівня та інші операції, пов’язані з його оптимізацією. Цей процес прийнято називати рефакторинг коду програми, без якого програма не буде оптимальною. Після виконання оптимізації, процес повторюється знову, тобто, кількість ітерацій буде такою, щоб, зрештою, забезпечити вихід оптимізованого програмного модуля з потрібною функціональністю.
Переваги використання TDD
Серед переваг використання методу TDD для створення програмного забезпечення можна виділити такі:
- Використання тестів знижує кількість помилок у коді, а, отже, зменшується час його налагодження та, зрештою, час розробки програми.
- Помилки виявляються на ранній стадії розробки, що практично виключає їх появу на завершальній стадії проекту або готовому продукті. Це може суттєво вплинути на вартість розробки програми.
- Тести дозволяють проводити рефакторинг коду, за винятком його пошкодження.
- Застосування методики сприяє покращенню основних характеристик коду – модульності, гнучкості та розширюваності.
- Застосування автоматизованих тестів сприяє покриттю всіх шляхів виконання коду, що забезпечує його повноту та достатність.
- Тести можуть стати гарною альтернативою документації до програмного забезпечення, яка, як відомо, часто застаріває.
Недоліки використання методу TDD
Як і будь-які методи або підходи до програмування, метод, що розглядається, також має недоліки. Виділимо деякі з них:
- Обмеженість застосування. Метод не підходить для використання в деяких областях, наприклад, у системах безпеки даних та для опису процесів. Це пов’язано з присутністю деяких додаткових некерованих факторів, наприклад, людського фактора для систем безпеки.
- Потрібен додатковий час на розробку та підтримку тестів. Тому перед застосуванням методики необхідно обґрунтувати та довести доцільність та ефективність її використання у конкретній ситуації.
- Збільшуються витрати на створення програм.
DDT
Data-Driven Testing (DDT) – це підхід до тестування програмного забезпечення, коли тестові дані окремо від окремих тестових сценаріїв і вони завантажуються з зовнішніх джерел. Цей підхід дозволяє використовувати різні дані для тестування одного тестового сценарію без необхідності зміни самого сценарію.
Основні аспекти Data-Driven Testing:
- Відокремлення тестових даних від тестових сценаріїв:Тестові дані зберігаються у відокремлених джерелах, таких як ексель-файли, CSV, бази даних або файли JSON/XML. Це дозволяє динамічно змінювати дані без редагування тестового коду.
- Множинні варіанти тестування з одним тестовим сценарієм:Тестовий сценарій може використовувати одну тестову процедуру, яка буде виконуватися з різними наборами даних.
- Параметризація тестів:Використання параметрів для передачі тестових даних у тестовий код, щоб виконати тести з різними значеннями.
- Покращення відтворюваності:Завдяки відокремленню тестових даних від коду тестування, відтворюваність стає кращою, оскільки тестові сценарії можуть бути запущені з різними наборами даних.
- Масштабованість тестування:Можливість запуску тестів на великій кількості даних для перевірки роботи програми при різних умовах.
У фреймворку Cypress можна використовувати підхід Data-Driven Testing для параметризації тестів, використовуючи дані з зовнішніх джерел. Ось приклад, як можна зробити це у Cypress:
describe('Data-Driven Testing в Cypress', () => {
const testData = [
{ username: 'user1', password: 'password1' },
{ username: 'user2', password: 'password2' },
// Додайте більше тестових даних за потребою
];
testData.forEach((data) => {
it(`Логін користувача ${data.username}`, () => {
cy.visit('/login');
cy.get('#username').type(data.username);
cy.get('#password').type(data.password);
cy.get('#loginButton').click();
// Додайте решту логіки для перевірки логіну за потребою
});
});
});У цьому прикладі тест Логін користувача буде виконаний для кожного набору тестових даних з масиву testData. Cypress автоматично запустить кожен тест з використанням різних даних, які ви визначили.
Для більш ефективного використання тестових даних можна використовувати зовнішні файли (наприклад, CSV, JSON або Excel), а потім зчитувати ці дані у тестовому коді для виконання тестів на основі цих даних. Ось приклад:
describe('Data-Driven Testing з зовнішніми даними в Cypress', () => {
it('Логін користувача з використанням зовнішніх даних', () => {
cy.fixture('users').then((users) => {
users.forEach((user) => {
cy.visit('/login');
cy.get('#username').type(user.username);
cy.get('#password').type(user.password);
cy.get('#loginButton').click();
// Додайте решту логіки для перевірки логіну за потребою
});
});
});
});В цьому прикладі cy.fixture(‘users’) зчитує дані про користувачів з файлу users.json, де містяться дані для логування, і виконує тест для кожного користувача, зчитаного з цього файлу.
Ці приклади показують основи використання Data-Driven Testing у фреймворку Cypress, який дозволяє параметризувати ваші тести та виконувати їх з різними наборами даних.
Переваги Data-Driven Testing (DDT):
- Масштабованість тестів:Дозволяє створювати велику кількість тестів, використовуючи різні вхідні дані для кожного тесту без необхідності створення окремого тесту для кожного набору вхідних даних.
- Покриття більш широкого спектру сценаріїв:Дозволяє охопити більш широкий спектр можливих сценаріїв використання програми за допомогою різних комбінацій тестових даних.
- Ефективність:Дозволяє використовувати однаковий набір тестів з різними даними, що полегшує та прискорює процес тестування.
- Легкість обслуговування тестів:Можливість зміни тестових даних без зміни тестового скрипту. Це зручно при випадкових або генерованих даних.
Недоліки Data-Driven Testing (DDT):
- Складність обслуговування даних:Підготовка та управління великими об’ємами тестових даних може бути важкою та витратною задачею.
- Неповне покриття:Недостатність тестових даних може призвести до недостатнього покриття важливих сценаріїв.
- Складність розуміння та підтримки:Іноді важко розуміти, який саме набір даних використовується для кожного тесту при аналізі неуспішних тестів.
- Потреба у стабільних даних:Якщо вхідні дані непостійні або змінюються, може бути складно підтримувати стабільність тестів.
Загалом, DDT може бути корисним для швидкої перевірки багатьох варіантів виконання програми, але його ефективність залежить від якості та стабільності тестових даних.
BDD
Behavior-Driven Development (BDD) – це методологія розробки програмного забезпечення, яка ставить на перший план співпрацю між розробниками, тестувальниками та бізнес-аналітиками, а також спрямована на розуміння поведінки системи з точки зору бізнес-вимог та специфікацій. BDD спрямований на вирішення проблем комунікації між стейкхолдерами, розробниками та тестувальниками, а також на створення продукту з вищою якістю.
Основні аспекти Behavior-Driven Development:
- Участь стейкхолдерів:BDD включає участь різних стейкхолдерів, таких як бізнес-аналітики, розробники та тестувальники, щоб домовитися про спільне розуміння вимог до продукту.
- Жива специфікація (Living Documentation):Специфікація проекту представлена у вигляді легко зрозумілих сценаріїв, які можна використовувати як документацію та тести. Це дозволяє стейкхолдерам зрозуміти, як має поводитися система.
- Спільний мовний формат:Використання загально прийнятого мовного формату (наприклад, Gherkin – набір ключових слів, таких як Given, When, Then) для написання специфікаційних сценаріїв.
- Постійний цикл ретельності:Застосування постійного циклу ретельності (Red-Green-Refactor) з метою вирішення вимог бізнесу та розроблення необхідного функціоналу.
- Тестування з бізнес-вимогами:Написання тестів, які відображають бізнес-вимоги, а не лише функціональні або технічні аспекти програми.
- Автоматизація тестів:Автоматизація тестів для перевірки специфікацій та вимог продукту, що дозволяє стежити за їх виконанням.
Процес роботи Behavior-Driven Development:
- Формування специфікаційних сценаріїв:Стейкхолдери спільно визначають специфікації системи у вигляді сценаріїв.
- Написання тестів на основі специфікацій:На основі специфікаційних сценаріїв створюються автоматизовані тести, які перевіряють відповідність програми вимогам.
- Реалізація функціоналу:Розробники реалізують необхідний функціонал, щоб тести пройшли успішно.
- Виконання тестів:Тести виконуються автоматично для перевірки відповідності реалізованого функціоналу специфікаціям.
- Повторення циклу:Цей процес повторюється для нових функцій або змін, що вносяться у вже існуючий продукт.
Переваги Behavior-Driven Development:
- Зменшення непорозумінь між стейкхолдерами.
- Збільшення якості продукту за рахунок відповідності бізнес-вимогам.
- Зменшення часу, необхідного для пошуку й виправлення дефектів.
Недоліки Behavior-Driven Development:
- Потребує часу та зусиль для формування та підтримки специфікацій.
- Залежно від якості специфікацій може виникати більше тестів та коду.
Behavior-Driven Development спрямований на створення високоякісного програмного забезпечення, що відповідає бізнес-вимогам, та поліпшення комунікації між усіма стейкхолдерами у процесі розробки.
У фреймворку Cypress можна реалізувати Behavior-Driven Development (BDD) за допомогою декількох інструментів, які допоможуть створити автоматизовані тести на основі специфікацій. Ось деякі інструменти для імплементації BDD у фреймворку Cypress:
- Cypress-Cucumber-Preprocessor:Це розширення для Cypress, яке дозволяє використовувати синтаксис Gherkin (Given-When-Then) для написання тестів.
- Дозволяє створювати чіткі, зрозумілі сценарії, що базуються на бізнес-вимогах.
- Цей препроцесор дозволяє тестам бути більш зрозумілими для бізнес-аналітиків та стейкхолдерів.
- Cypress-Cucumber-UI:Графічний інтерфейс для Cypress, що дозволяє створювати та відлажувати сценарії, написані в форматі Gherkin.
- Це інструмент управління тестами, який спрощує роботу з Gherkin-сценаріями.
- Cypress-Gherkin:Це розширення для Cypress, яке дозволяє використовувати синтаксис Gherkin для створення та виконання тестів у стилі BDD.
Ці інструменти можна комбінувати для створення автоматизованих тестів на основі специфікацій Gherkin у фреймворку Cypress, що допомагає реалізувати основні принципи Behavior-Driven Development та створювати чіткі, зрозумілі тести, які відповідають бізнес-вимогам.
Приклади використання Cypress-Cucumber-Preprocessor
Підготовка проекту:
- Встановлення Cypress та Cypress-Cucumber-Preprocessor:
Встановіть Cypress і Cypress-Cucumber-Preprocessor у вашому проекті через npm:
npm install cypress --save-dev
npm install cypress-cucumber-preprocessor --save-dev2.Конфігурація Cypress:
У файлі cypress/plugins/index.js додайте налаштування Cypress-Cucumber-Preprocessor:
const cucumber = require('cypress-cucumber-preprocessor').default;
module.exports = (on, config) => {
on('file:preprocessor', cucumber());
};3.Створення тестів з використанням Gherkin:
Створіть каталог cypress/integration і додайте файл з розширенням .feature для написання сценаріїв.
Приклад використання Gherkin у Cypress з Cypress-Cucumber-Preprocessor:
Припустимо, у вас є файл login.feature з таким вмістом:
Feature: Логін користувача
Як зареєстрований користувач
Я хочу увійти до системи
Scenario: Успішний логін
Given Я відкриваю сторінку логіну
When Я вводжу свій email "user@example.com" та пароль "password"
And Натискаю кнопку "Увійти"
Then Я повинен зайти на сторінку з особистим кабінетомСтворення тестового файлу для цього сценарію:
Створіть файл login.js у каталозі cypress/integration з наступним вмістом:
import { Given, When, Then } from 'cypress-cucumber-preprocessor/steps';
Given('Я відкриваю сторінку логіну', () => {
cy.visit('/login');
});
When('Я вводжу свій email {string} та пароль {string}', (email, password) => {
cy.get('#email').type(email);
cy.get('#password').type(password);
});
And('Натискаю кнопку {string}', (buttonText) => {
cy.contains('button', buttonText).click();
});
Then('Я повинен зайти на сторінку з особистим кабінетом', () => {
cy.url().should('include', '/dashboard');
});Ось приклад параметризованого сценарію у форматі Gherkin та його відповідний тестовий файл Cypress з використанням Cypress-Cucumber-Preprocessor:
Файл login.feature (Gherkin):
gherkinCopy code
Feature: Логін користувача
Як зареєстрований користувач
Я хочу увійти до системи
Scenario Outline: Успішний логін з різними користувачами
Given Я відкриваю сторінку логіну
When Я вводжу свій email "<email>" та пароль "<password>"
And Натискаю кнопку "Увійти"
Then Я повинен зайти на сторінку з особистим кабінетом
Examples:
| email | password |
| user1@example.com | password1 |
| user2@example.com | password2 |
| user3@example.com | password3 |
Файл login.js(Cypress тест):
javascriptCopy code
import { Given, When, Then } from 'cypress-cucumber-preprocessor/steps';
Given('Я відкриваю сторінку логіну', () => {
cy.visit('/login');
});
When('Я вводжу свій email {string} та пароль {string}', (email, password) => {
cy.get('#email').type(email);
cy.get('#password').type(password);
});
And('Натискаю кнопку {string}', (buttonText) => {
cy.contains('button', buttonText).click();
});
Then('Я повинен зайти на сторінку з особистим кабінетом', () => {
cy.url().should('include', '/dashboard');
});
Цей сценарій login.feature має параметризовану таблицю <email> та <password>, яка містить різні комбінації логінів. Кожен рядок таблиці Examples визначає окремий тестовий випадок.
У файлі login.js, використовуючи Cypress та Cypress-Cucumber-Preprocessor, ми визначаємо кроки для кожної фрази Gherkin (Given, When, Then тощо) та виконуємо необхідні дії для кожного кроку.
Це дозволяє вам створювати один тестовий сценарій з багатьма тестами, які можуть бути виконані з різними даними, щоб перевірити різні умови для вашого логіну.
Background в Gherkin дозволяє визначити кроки, які повторюються у кожному сценарії у файлі фіч (*.feature). Ось приклад використання Background у файлі Gherkin:
Файл login.feature (Gherkin):
gherkinCopy code
Feature: Логін користувача
Як зареєстрований користувач
Я хочу увійти до системи
Background:
Given Я відкриваю сторінку логіну
Scenario Outline: Успішний логін з різними користувачами
When Я вводжу свій email "<email>" та пароль "<password>"
And Натискаю кнопку "Увійти"
Then Я повинен зайти на сторінку з особистим кабінетом
Examples:
| email | password |
| user1@example.com | password1 |
| user2@example.com | password2 |
| user3@example.com | password3 |
Файл login.js(Cypress тест):
javascriptCopy code
import { Given, When, Then } from 'cypress-cucumber-preprocessor/steps';
Given('Я відкриваю сторінку логіну', () => {
cy.visit('/login');
});
When('Я вводжу свій email {string} та пароль {string}', (email, password) => {
cy.get('#email').type(email);
cy.get('#password').type(password);
});
And('Натискаю кнопку {string}', (buttonText) => {
cy.contains('button', buttonText).click();
});
Then('Я повинен зайти на сторінку з особистим кабінетом', () => {
cy.url().should('include', '/dashboard');
});
В даному прикладі, Background визначає кроки, які повторюються у кожному сценарії (Scenario) у файлі login.feature. У цьому випадку, кожен сценарій розпочинається з відкриття сторінки логіну (використовуючи крок Given Я відкриваю сторінку логіну з Background). Після чого виконуються унікальні кроки для кожного сценарію з таблиці Examples.
Файл login.js відображає Cypress-тест, який відповідає сценаріям, описаним у файлі login.feature, та містить код для виконання кожного кроку з Gherkin.
POM
Page Object Model (POM) – це шаблон проектування в автоматизованому тестуванні, де кожна веб-сторінка програми або веб-сайту моделюється в окремому класі. Цей підхід розділяє логіку тестів від локаторів елементів сторінки, що дозволяє підтримувати та управляти автоматизованими тестами більш ефективно. Ось детальніше про аспекти Page Object Model:
Основні аспекти Page Object Model:
- Розділення логіки тестування та локаторів:Page Object Model дозволяє відокремити логіку тестування від реалізації веб-елементів та їх локаторів, що полегшує розуміння, підтримку та модифікацію коду.
- Повторне використання коду:Шаблон Page Object дозволяє використовувати сторінкові об’єкти у багатьох тестах, забезпечуючи повторне використання коду та уніфікацію логіки тестування.
- Простота підтримки:Зміни на сторінці (наприклад, зміна локатора елемента) вносяться тільки в сторінковий об’єкт, що робить підтримку тестів простішою.
- Зрозумілість та читабельність коду:Локатори елементів та дії на сторінці описуються в окремому класі, що робить код більш зрозумілим та читабельним.
- Масштабованість тестових скриптів:За допомогою Page Object Model можна легко розширювати тестові скрипти на нові сторінки без необхідності повторювати код.
- Зручність у використанні для командної роботи:Розділення функціоналу сторінки на окремі класи дозволяє команді одночасно працювати над різними частинами веб-сторінки без конфліктів.
Page Object Model – це ефективний методологічний підхід до автоматизованого тестування, який полегшує підтримку, підвищує стабільність та зрозумілість автоматизованих тестів.

Переваги Page Object Model (POM):
- Зменшення дублювання коду:Page Object Model дозволяє створювати окремі класи для кожної сторінки або компонента, що значно зменшує дублювання коду та сприяє повторному використанню.
- Зрозумілість та підтримка коду:Розділення логіки тестів від локаторів елементів робить код більш зрозумілим та підтримуваним. Модифікація локаторів відбувається лише в одному місці, що спрощує роботу з кодом.
- Підвищення стабільності тестів:Page Object Model дозволяє розробляти більш стабільні тестові скрипти, оскільки зміни на сторінці можна вносити без впливу на більшість тестів, тільки зміни в Page Object класі.
- Простота використання для командної роботи:Розділення функціоналу сторінки на окремі класи дозволяє різним членам команди працювати з окремими частинами веб-сторінки без конфліктів.
- Підтримка тестів на різних платформах:Page Object Model дозволяє підтримувати один і той же тестовий скрипт на різних платформах (наприклад, веб, мобільні додатки) через відокремлення логіки тестування від інтерфейсів.
Недоліки Page Object Model (POM):
- Затратність розробки:Іноді створення та підтримка Page Object моделей може бути затратною у порівнянні з написанням простих тестів без використання цього шаблону.
- Підвищена складність для початківців:Використання Page Object Model може бути складним для тестувальників з малою кількістю досвіду в автоматизації.
- Підтримка та оновлення:Потреба у постійному оновленні та підтримці Page Object класів змінюється з веб-сайтами та додатками, що може вимагати витрат на підтримку.
- Можливе перевантаження класів:Якщо не управляти правильно, класи Page Object можуть стати перевантаженими, важкими для розуміння та підтримки.
Незважаючи на деякі недоліки, Page Object Model залишається потужним та корисним підходом для структурування автоматизованих тестів, полегшуючи підтримку та збереження стабільності тестового коду.
Приклад реалізації Page Object Model у фреймворку Cypress
Ось приклад структури Page Object Model у фреймворку Cypress:
Створіть папку з назвою, наприклад, pages, де будуть розташовуватися класи сторінок вашого веб-додатка. Наприклад, якщо у вас є сторінка логіну та головна сторінка, то можна створити два файлу в цій папці: LoginPage.js та HomePage.js.
LoginPage.js:
class LoginPage {
getEmailInput() {
return cy.get('#email');
}
getPasswordInput() {
return cy.get('#password');
}
getLoginButton() {
return cy.get('button[type="submit"]');
}
visit() {
cy.visit('/login');
}
fillEmail(email) {
this.getEmailInput().type(email);
}
fillPassword(password) {
this.getPasswordInput().type(password);
}
clickLoginButton() {
this.getLoginButton().click();
}
// Інші методи взаємодії з елементами на сторінці логіну...
}
export default new LoginPage();HomePage.js:
class HomePage {
verifyWelcomeMessage() {
cy.contains('h1', 'Welcome').should('be.visible');
}
// Інші методи для перевірки елементів на головній сторінці...
}
export default new HomePage();Використання в тестах:
javascriptCopy code
import LoginPage from '../pages/LoginPage';
import HomePage from '../pages/HomePage';
describe('Login Test', () => {
it('should login with valid credentials', () => {
LoginPage.visit();
LoginPage.fillEmail('your_email@example.com');
LoginPage.fillPassword('your_password');
LoginPage.clickLoginButton();
// Перевірка після успішного входу
HomePage.verifyWelcomeMessage();
// Інші перевірки на головній сторінці...
});
});Такий підхід дозволяє створювати класи для кожної сторінки вашого веб-додатка та включати в них методи для взаємодії з елементами сторінки. Під час написання тестів, ви можете використовувати ці методи для взаємодії з елементами та перевірки їх стану, спрощуючи тим самим підтримку та розвиток автотестів у майбутньому.
Додаткові матеріали
What is Test Driven Development (TDD)?
Domain Driven Testing for Test Automation
What is BDD? (Behavior-Driven Development)